Conversational AI Chatbot 🤖
Project Details
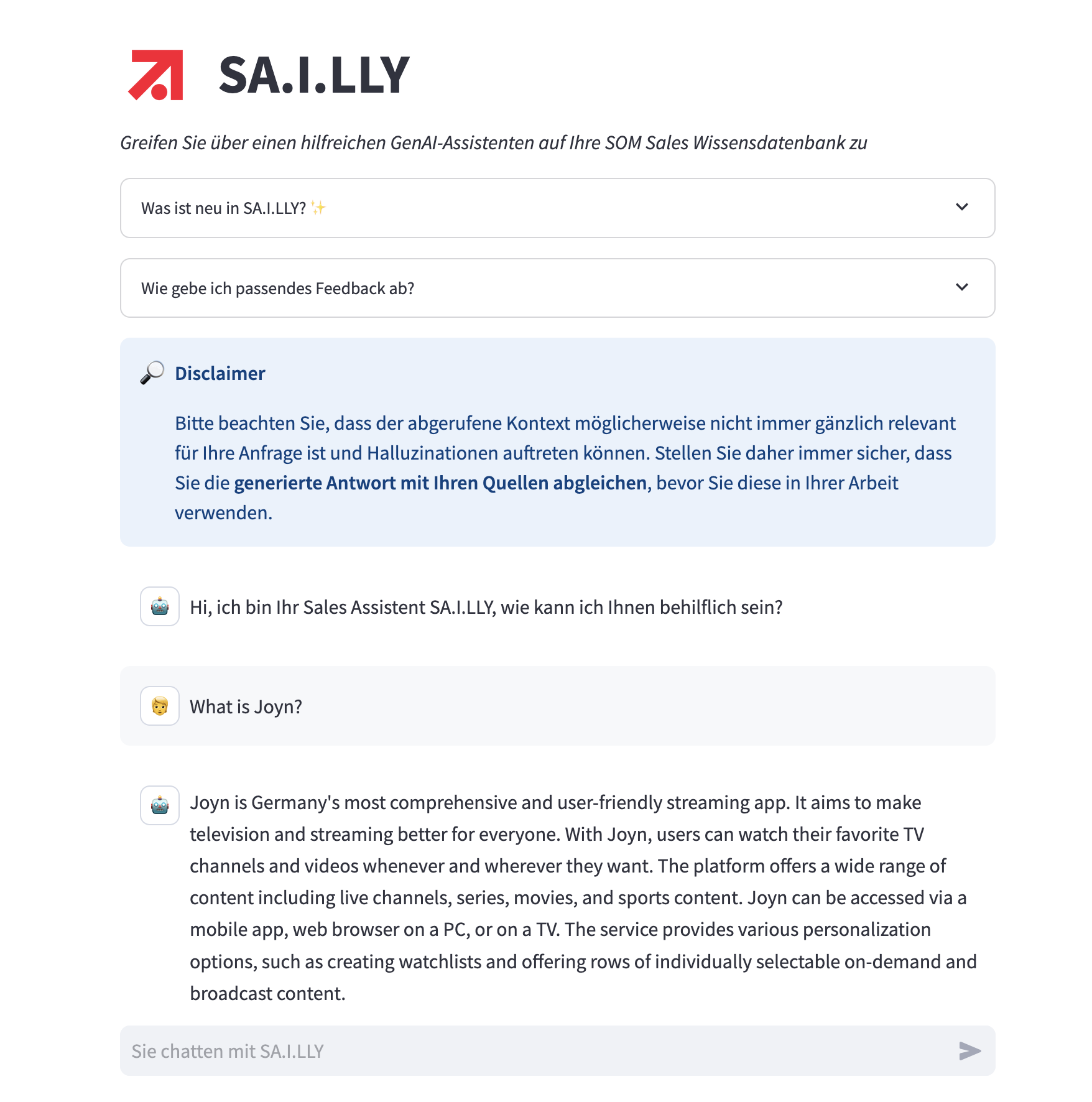
Sailly is a web-based chat interface built using Streamlit and powered by Retrieval-Augmented Generation (RAG). It enables the sales department to quickly retrieve and answer questions from internal knowledge bases, improving efficiency and decision-making. The RAG system is developed using LlamaIndex and supports multiple data sources, including Confluence Spaces, PDFs, Excel files, and PowerPoint slides. Additionally, images embedded in these sources are transcribed, allowing users to extract insights from images and graphs through text-based queries.

The application is hosted in AWS using Docker and AWS ECS, while the knowledge base is stored in a PostgreSQL database on AWS RDS. It leverages OpenAI's text-embedding-ada-002 for vector embeddings and Anthropic's claude-3.5-sonnet for both response generation and image transcription.
Key Features
- Multi-Source Knowledge Integration: Supports ingestion from Confluence Spaces, PDFs, Excel, and PowerPoint slides.
- Image Transcription & Retrieval: Extracts insights from images and graphs by transcribing embedded text for searchable answers.
- Agentic Workflow: Dynamically fetches relevant information across multiple knowledge bases.
- Automated Syncing: Keeps knowledge bases up to date through a scheduled AWS Lambda function.
- Performance Evaluation Framework: Measures RAG accuracy using QA pairs for both single and multi-source evaluations.
My Contribution
I took full responsibility for leading the technical development of the product, from the initial kickoff meeting to the automated deployment of the application. This included selecting the appropriate frameworks, designing the system architecture, developing the first MVP, and evaluating system performance. Together with two colleagues, we built a scalable and extensible framework that allows seamless integration of new knowledge sources based on customer needs. Our design extensively utilizes Python functional composition and higher-order functions, ensuring modularity and reusability in our implementation.
Challenges and Solutions
- Maintaining RAG Performance: The integration of new data sources could degrade retrieval quality. To mitigate this, we developed an evaluation framework using QA pairs to assess performance across individual and combined sources.
- Extracting Insights from Images: Customers wanted the ability to query graphical content (e.g., "How much revenue did Joyn reach in 2025?"). We implemented an image transcription pipeline that converts images into searchable text and integrates them into the knowledge base.
- Automated Knowledge Syncing: Ensuring up-to-date information required an independent sync mechanism. We implemented an AWS Lambda function to refresh the knowledge base daily.
- Handling Multiple Knowledge Bases: Managing diverse sources required an intelligent retrieval mechanism. We employed an agentic workflow to fetch relevant information dynamically across all sources.
Outcome
- The application saves an average of 40 minutes per day per Sailly user. With 80 employees in the sales department, this results in a total of 11,680 hours saved per year.
- New knowledge sources can be integrated effortlessly, making the solution adaptable to evolving business needs.
- The system is designed to be highly scalable and can be repurposed for different business use cases or departments.
Technologies
Python Generative AI Retrieval-Augmented Generation (RAG) LlamaIndex LLMs Anthropic Claude Azure OpenAI MLOps Vector Database PostgresDB Embeddings Streamlit AWS Bedrock AWS ECS AWS ECR AWS RDS AWS Secrets Manager AWS Lambda Docker ETL Image Transcription